The Problem
Manual Outreach Doesn't Scale
During an internship, I inherited the outreach workflow. Open Instagram. Search a competitor's followers. Tap a profile. Read the bio. Decide if they're a lead. Copy their handle into a spreadsheet. Repeat 300 times. Then open each one again and send a personalized DM.
One person could send maybe 40–50 DMs a day before burning out or getting rate-limited. The company needed 200. Every day. Without getting flagged.
So I built a system.
Stage 1
The Scraper
A Playwright headless browser opens Instagram, navigates to a target account's follower list, and starts scrolling. For each profile it extracts the username, bio, follower count, and following count.
The tricky part is not getting caught. Instagram aggressively rate-limits automation. Every action has a randomized delay — sleep(rand(45, 90)) between profile checks. Proxy rotation cycles through residential IPs. The browser fingerprint rotates user agents and viewport sizes. It moves like a human scrolling their feed at 2 AM.
Stage 2
The Qualifier
Raw follower data is noisy. Most accounts are bots, personal pages, or outside the target demographic. The qualifier runs a two-pass filter:
Pass 1 — hard filters. Follower count within range. Bio contains relevant keywords. Account is public. Not already in the CRM.
Pass 2 — GPT qualification. The bio and account metadata go to the GPT API, which makes a judgment call: is this person likely a qualified lead? It catches nuance that keyword matching misses — a bio that says “helping brands grow” is different from “growing my garden.”
Qualified leads get pushed to a Google Sheets CRM via the Sheets API. A webhook fires for real-time Slack notifications.
Stage 3
The Seed List
The best leads have followers who are also good leads. When the qualifier tags someone as high-quality, their profile gets added to a seed list. The scraper picks up seed accounts automatically and scrapes their followers next.
This creates a compounding effect. Each batch of qualified leads generates the next batch of targets. The pipeline feeds itself. What started as a list of 5 competitor accounts grew into thousands of qualified profiles over a few weeks.
Stage 4
The DM Bot
A separate process reads the Google Sheets CRM, filters for leads that haven't been contacted, and sends personalized DMs. 200 per day, every day, with zero manual intervention.
Each message is built from templates with personalization tokens — the lead's name, something from their bio, a tailored hook. Random delays between 45–90 seconds per message keep the pattern indistinguishable from organic activity. The bot marks each lead as contacted in the sheet so nothing gets sent twice.
System Overview
Architecture
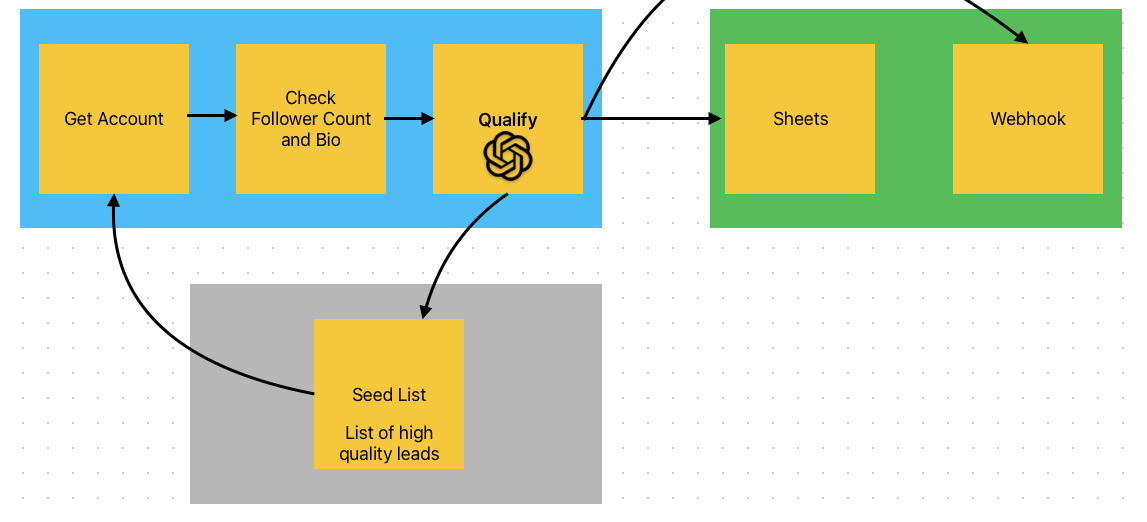
Full pipeline flow: scrape → qualify (GPT) → Google Sheets CRM → DM bot. Seed list feeds qualified leads back into the scraper.